Структура поисковых сервисов Интернета. Поисковые машины и каталоги.
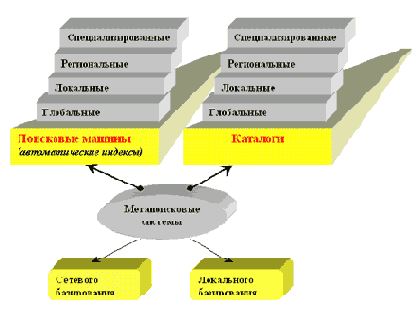
Рис.1 Организация поисковых сервисов Интернета.
Согласно схеме на рис.1 реальными носителями информации о ресурсах, которыми располагает Сеть, являются поисковые машины (автоматические индексы) и каталоги. В силу того, что они, хотя и различными средствами, самостоятельно обеспечивают все этапы обработки информации от ее получения с узлов-первоисточников до предоставления пользователю возможности поиска, их часто называют автономными системами.
Автономные поисковые системы могут различаться по принципу отбора информации, который в той или иной степени присутствует и в алгоритме сканирующей программы автоматического индекса, и в регламенте поведения сотрудников каталога, отвечающих за регистрацию. Как правило, сравниваются два основных показателя: пространственный масштаб, в котором работает ИПС, и ее специализация.
Сначала о масштабе. При формировании информационного массива поисковая система может следить за обновлением наперед заданного набора документов, каталогов или конечного числа узлов, отобранных по какому-либо принципу. Такие системы, реализованные в Интернете, несколько условно можно назвать локальными. Глобальные поисковые системы в отличие от локальных решают более трудоемкую задачу - по возможности наиболее полный охват ресурсов всего информационного поля Сети (WWW, FTP или другого), которое они обслуживают. Следствием этого становится возрастание роли механизма, который используется глобальной системой для постоянного увеличения числа подконтрольных узлов.
Построение региональных и специализированных поисковых сервисов предполагает активную фильтрацию информации.
Специализация поисковой системы на базе какого-либо профиля или тематики, будь то поиск людей и организаций, компьютерного "железа" или файлов мультимедиа в формате MP3, теоретически может происходить как на глобальной, так и на локальной основе. Разумеется, систему проще построить и сопровождать на ограниченном пространстве обновляемых узлов, что обычно и реализуется на практике.
Региональными поисковыми службами информация фильтруется в основном на основе распознавания домена верхнего уровня сервера, например, ru и su для России. Серьезным недостатком таких систем является неучет ими большого количества ресурсов, размещаемых региональными разработчиками в традиционно популярном домене com.
Региональные мотивы нередко привносятся и в сервис глобальных ИПС. Система Lycos, например, ранжирует результаты из списка отклика в зависимости от того, из какого региона поступил запрос.
Еще одно важное направление в деле регионализации поисковых сервисов связано с разработкой узлов-зеркал (mirrors) для наиболее популярных поисковых систем. Зеркала должны содержать точную копию индекса первичной ИПС и гарантировать быстрое обслуживание обращений, поступающих из определенной географической зоны. На практике обновление индекса зеркальной системы всегда происходит с запаздыванием. Так, для австралийского зеркала поисковой машины AltaVista, лидера по количеству зеркал, оно обычно составляет 1-2 дня при безаварийной работе, и это лучшее время. Альтернатива между скоростью работы и полнотой данных становится значимой для пользователя, если он имеет возможность обратиться и к зеркалу, и к первоисточнику.
В прошлый раз мы отдельно отметили, что именно становление автоматических индексов, охватывающих ресурсы определенного типа, имеет знаковый характер. Это событие всегда было связано с фазой бурного развития соответствующего информационного поля, а на текущий момент - с пространством WWW. Реально лишь высокая скорость автоматического индексирования документов с помощью программ-роботов способна обуздать информационный хаос в Сети. Применение же при поиске каталогов ресурсов в "чистом виде", без возможности поиска по ключевым словам, скорее напоминает серфинг, а не серьезную работу с информацией. Тем не менее роль каталогов, заметно упавшая на глобальном уровне накопления данных, остается важной для регионального поиска.
Каталоги WWW, содержащие большое количество записей, например, Yahoo! (более 750 тыс.) или русскоязычный АУ (более 20 тыс.), нередко размещают на своих страницах локальные поисковые машины, реализуемые в виде традиционных шаблонов. Поскольку визуально и в работе последние мало чем отличаются от шаблонов на автоматических индексах, сами каталоги такого типа часто неверно называют поисковыми машинами. Дело здесь не в чистоте терминологии, которая неинтересна рядовому пользователю. Проблема в том, что непонимание того, как внутренне функционирует поисковая система, влечет за собой неконтролируемую потерю информации. Так, следуя ошибочному определению, можно легко поставить на одну ступеньку глобальный автоматический индекс Northern Light и "поисковую машину"-каталог Yahoo. Это означает пытаться сравнивать в едином ключе сервисы, нацеленные на решение совершенно разных, по крайней мере, с точки зрения профессионального поиска, задач. Локальная поисковая машина каталога предполагает поиск по ключевым словам, входящим в названия разделов, узлов и другим немногочисленным данным, которые вводятся при регистрации. В то время как в автоматическом индексе информация об отдельном узле намного шире - в идеале вплоть до единичного слова каждого документа, причем с учетом специальных полей Web-страницы и режима обновления данных.
Простота организации локальной по Web-узлу поисковой машины делает ее частым атрибутом не только каталогов, но и самых рядовых сайтов. Если сравнить содержимое индекса локальной системы с информацией о том же самом узле из индекса глобальной поисковой машины, то локальная система имеет все шансы превзойти глобальную и по полноте данных, и по частоте их обновления.
Благодаря этому довольно часто наиболее эффективный путь от запроса на глобальной ИПС к конечному блоку информации лежит через промежуточное звено -локальный поисковый сервис узла (см. схему на рис.2). Под внутренним на схеме понимается поиск внутри конечного объекта, если это возможно, например, поиск по тексту Web-страницы, поддерживаемый большинством браузеров.
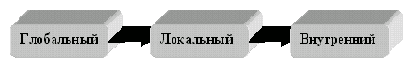
Рис.2. Уровни поисковой процедуры.
Чрезвычайно важной проблемой Сети является интеграция различных поисковых сервисов в единую систему. Для Паутины 1999 год уже стал знаменателен одним неординарным событием - при участии 15 крупнейших поисковых систем Интернета в феврале стартовал проект SESP (Search Engine Standards Project), призванный стандартизировать работу поисковых служб. Материалы о нем можно найти по адресу http://www.searchenginewatch.com/standards/990204.html.
Уже первые документы проекта дают понять, что задачей стандарта является максимально сблизить синтаксис и возможности поисковых языков различных ИПС. В частности, одним из обязательных требований становится поддержка любой поисковой системой единых команд запросов, локализующих узел по его доменному имени, а документ - по URL.
Понятно, что даже это простое соглашение поставило бы учет и контроль информации в масштабе Сети на принципиально новый уровень.
Теоретически привлекает перспектива создания сверхмощной глобальной поисковой системы, которая бы была способна сопровождать Сеть в ее полном информационном объеме. Однако на практике это пока невозможно, и решение проблемы интеграции смещается в сторону разработки метапоисковых систем (см. рис.1).