Проблема N 2: язык поисковых запросов
Ситуация может осложниться тем, что на поисковом сервере вы не найдете исчерпывающего описания того, как работают операторы языка запросов.
Даже на уже зрелых, не первый год работающих ИПС, с этим можно столкнуться. Рассмотрим на примере AltaVista, как это может стать источником определенных проблем.
Несмотря на недавнее появление графического фильтра (см. рис.2), многие пользователи системы продолжают эксплуатировать прозрачный по своей природе оператор image, позволяющий находить в индексе графические файлы. На этот счет справка AltaVista исчерпывает себя тем, что рекомендует ввести в шаблон запрос, в котором вслед за указанным оператором должно следовать имя или часть имени искомого файла. Таким образом, для поиска файла с изображением акрополя следует задать запрос в виде image: acropolis.
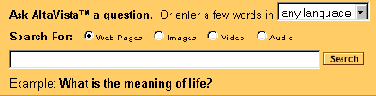
Рис.2 Шаблон простого поиска AltaVista (www.altavista.com) с фильтрами и меню выбора языка поиска.
Увеличит ли наши шансы на успех, знание того, как реально отрабатывает оператор image? Если посмотреть на откликнувшиеся документы, а затем на их HTML-источник, то легко убедиться, что в каждом из них в месте вставки графического образа присутствует элемент <IMG>. Внутри него в качестве обязательного атрибута стоит URL, с которого собственно и извлекается сам файл:
<IMG SRC="http://www.citforum.ru/buildings/acropolis.gif">
Фактически же Web-страница дает отклик, если ключевое слово входит не только в имя файла, но и в название любого каталога и в доменное имя сервера, содержащихся в URL элемента <IMG>. То есть документ, включающий в себя приведенную выше строку, откликнулся бы и на запрос image:buildings. Следовательно, поиск по имени каталога, которое так же как и имя файла несет смысловую нагрузку, позволяет получить графические данные, которые нельзя извлечь в первом случае. Предположим, что Web-мастер неосторожно назвал искомый файл acr1.gif, но разумно положил его в каталог buildings.Тогда по запросу image:buildings могут откликнуться релевантные документы с изображением акрополя, вставленным в Web-страницу с помощью строки:
<IMG SRC="http://www.citforum.ru/buildings/acr1.gif">
В расширенном поиске AltaVista используются логические операторы и скобки. Однако на сервере ничего не говорится о том, допустимо ли их применять внутри специальных полей поиска, таких как поле image. Уже заведомо зарегистрированный в индексе графический файл, найденный ранее, можно использовать для проверки работоспособности отдельных поисковых запросов. Так, если предположить, что файл с URL из последнего примера существует, то
тестовый запрос в виде image:( buildings AND acr1) должен дать корректный ненулевой отклик, и, таким образом, подтвердить, что комбинирование операторов допустимо. На практике это действительно возможно.
Хотелось бы еще раз подчеркнуть, что речь здесь идет не о порочности отдельных поисковых систем, а о конструктивном подходе к разрешению возникающих вопросов. При этом нередки и ситуации, которые предугадать крайне сложно.
Если, скажем, на той же AltaVista организовать поиск по ключевому слову "президент" (оно специально выбрано в качестве тестового как довольно распространенное), легко убедиться, что отклик зависит от двух факторов: какой язык выбран в меню шаблона (см. рис.2 справа вверху) - русский (Russian) или любой (any language), а также какая русская кодировка установлена в меню браузера. Результаты поиска приведены в таблице 1.
| Кодировка/Язык | Русский (Russian) | Любой (Any) |
| Windows-1251 | 47 | 583 |
| Koi8-r | 3 | 52 |
Анализ списка отклика показывает, что, во-первых, при вводе запроса только в одной кодировке неминуемо теряются данные. Во-вторых, становится ясно, как система идентифицирует тот или иной язык документа. Оказывается, если некоторая начальная часть документа написана на языке, отличном от русского, то этот документ уже не описывается ИПС как русскоязычный. Как результат этой недокументированной особенности, максимальный отклик индекса при поиске по русскоязычному термину достигается при установке пункта меню "any language", а не "Russian".
В шаблоне расширенного поиска популярной бизнес-ориентированной системы Open Text Livelink Pinstripe (OTLP) (рис.3) также скрыты некоторые проблемы, никак не освещенные в справочном материале ИПС .
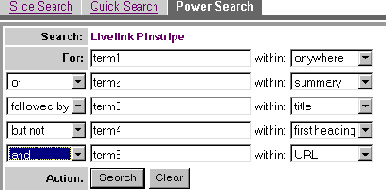
Рис. 3. Шаблон расширенного поиска OTLP (http://pinstripe.opentext.com/search/power.html) с модельным запросом.
Как видно из рисунка, шаблон позволяет задать свое поле поиска для каждого термина, а затем связать термины с помощью логических операторов. Однако, как только терминов становится больше двух - возникает вопрос, в какой последовательности будут отрабатывать операторы, и соответственно, что из себя будет представлять результат. Даже для такого простого запроса как term1 AND term2 OR term3 разумно предположить двоякую интерпретацию, которую можно проиллюстрировать с помощью выделения в скобки логических единиц (в самом шаблоне скобки не применяются). И вариант (term1 AND term2) OR term3, и вариант term1 AND (term2 OR term3) кажутся приемлемыми, давая при этом совершенно разный отклик. Тестовый запрос и последующий анализ откликнувшихся документов показывает справедливость первого варианта, т.е. что операторы выполняются по мере своего появления в шаблоне, и в документе будут присутствовать либо term1 и term2 одновременно, либо term3. Как в таком шаблоне вводить запросы с участием фраз (а это возможно), автор предлагает выяснить читателям самостоятельно. В данном случае приходится констатировать очевидную небрежность разработчика по отношению к пользователям системы.
Подавляющее большинство ИПС Интернета сегодня активно работает с так называемыми стоп-словами (stop-words). К последним относят служебные части речи, которые не несут смысловую нагрузку, а также некоторые наиболее общеупотребительные в Сети слова, такие как information, Internet, Web, business и другие. Известно, что AltaVista, Excite, HotBot и Lycos применяют в работе технику стоп-слов, а Infoseek и NorthernLight ее не практикуют.
При появлении стоп-слов в поисковом запросе без специальных ухищрений ИПС может не учитывать их при поиске и ранжировании результатов, иногда информируя об этом пользователя, иногда - нет. В целом неучет стоп-слов при обработке запроса сокращает время поиска и повышает релевантность отклика. Однако, стоит вам захотеть отыскать что-нибудь вроде классической фразы Шекспира "to be or not to be", состоящей только из стоп-слов, и вы уже не владеете ситуацией.
Хотя стоп-слова и могут игнорироваться в простых запросах, в индексе полнотекстовой ИПС они присутствуют наряду с остальными. Такой системой является, например, AltaVista (индексируются все слова документа). HotBot в свою очередь, напротив, индексирует все, кроме стоп-слов.
Тем не менее и HotBot выполняет полнотекстовое индексирование отдельных значимых полей документа, так что запросы со стоп-словами, оформленные в виде фразы, дают и на этой ИПС результативный отклик.
Перечень стоп-слов не стандартизован, так что он может быть оригинальным для каждого сервиса. Разработчики редко приводят сведения об этом аспекте работы ИПС, однако при необходимости поиск по ключевым словам stop, words плюс название интересующей вас поисковой машины позволяет обнаружить в Сети версии соответствующих перечней.
Наиболее общие принципы выхода из проблемной ситуации следующие: по возможности избегать употребления стоп-слов в запросах, исключить применение логических операторов типа and, or, not и других в тех шаблонах, в которых они не поддерживаются и будут восприняты как стоп-слова.
Если же без стоп-слов в запросе нельзя обойтись, то следует включить их во фразу, что во многих системах означает заключение в кавычки. В отдельных случаях полезно протестировать работу шаблонов простого и расширенного поиска ИПС, в которых техника поддержки стоп-слов может быть различной.