Проблема N 1: наполнение базы данных
Любая поисковая машина или каталог регламентируют свою работу по сбору данных из Сети. Очевидно, что формирование поискового образа информационного объекта, или, другими словами, его "отражения" в "зеркале" поисковой системы неизбежно связано с некоторыми искажениями. По сути главным при этом становится вопрос о том алгоритме, на основе которого создается поисковый образ. Объектом-оригиналом при этом может стать как Web-страница, так и файл "закрытого" формата, который не доступен для проникновения сканирующих программ ИПС, например, видео или аудио-запись. Определенный шаблон обычно используется и при построении поискового образа для физического лица или компании в момент их регистрации в поисковой службе. Отсечение, фильтрация информации от оригинала свойственны всем без исключения ИПС, в том числе и полнотекстовым системам глобального охвата и самого общего назначения.
Фильтрация может регламентироваться как на техническом, так и на лингвистическом уровне, однако задача у нее одна -при минимальных материальных затратах добиться реальной эффективности поиска.
В связи с этим на практике часто возникает вопрос - что становится причиной неудачного поиска: отсутствие ли в Сети с высокой вероятностью на данный момент времени информации, релевантной запросу, или то, что эта информация потенциально не доступна для рассматриваемой поисковой системы. "Подводным камнем" этот аспект становится тогда, когда получен ненулевой отклик на поисковый запрос, а доля недополученных данных оказывается неконтролируемой. Некоторый свет на особенности работы глобальных ИПС проливает сравнительный анализ их возможностей, который был приведен в прошлом выпуске. Однако, если детали алгоритма фильтрации не известны, наиболее чувствительные потери данных возникают именно при использовании специализированных поисковых служб.
Рассмотрим несколько примеров. Немало специализированных систем имеют собственный интерфейс для ввода поисковых запросов. Тем не менее можно считать веянием времени, когда многие подобные сервисы интегрируются в шаблоны глобальных ИПС в виде фильтров. Такими возможностями всегда был известен HotBot, недавно соответствующие элементы были внедрены на AltaVista, есть они и на Еxcite. Постоянно расширяется набор фильтров поисковой системы Lycos (см. рис.1), на которой мы остановимся подробнее.
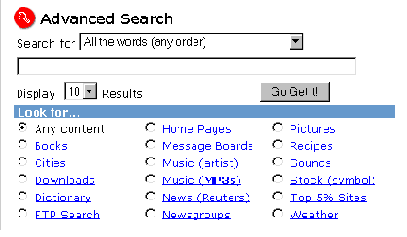
Рис.1. Шаблон расширенного поиска на Lycos с поддержкой многочисленных фильтров (http://lycospro.lycos.com/).
Представьте себя на месте пользователя, впервые пришедшего на такую известную глобальную поисковую систему, как Lycos, с желанием найти в Сети сведения о некотором книжном издании. Введя соответствующие ключевые слова и выбрав фильтр "Books", мы получаем отклик, который при отсутствии дополнительной информации нельзя расценить иначе, как получение данных о книгах, собранных по всему Интернету. Интересно задать вопрос, а может ли в масштабе Сети автоматически вестись отбор таких сведений? Если говорить только о пространстве WWW, то в большинстве случаев программы-пауки, сканирующие Сеть, используют для распознавания типа данных специальные элементы языка HTML, с помощью которых в Web-страницу внедряются определенные информационные блоки. Название элемента может нести смысловую нагрузку и отождествляться с типом информации. Так, если бы гипотетически существовал элемент HTML book, заключающий в себе сведения о книге и ее авторе, он мог бы размещаться на странице и в простейшем случае иметь вид:
<book> Название книги и автор</book>
(сами элементы <book> в окне браузера не должны отображаться). При этом вся информация о книгах, публикуемая таким образом в WWW, могла бы благополучно и без участия человека накапливаться в базе данных ИПС. Но элемента book в стандарте HTML пока не существует. Следовательно, приходится прибегать либо к "ручному" отбору, либо к автоматическому просмотру некоторых наперед заданных каталогов отдельных узлов, и, возможно, имеющих отношение к продаже книжной продукции или библиотекам.
В случае Lycos все гораздо проще. Поиск происходит всего навсего по одному единственному узлу компании (www.barnesandnoble.com), заинтересованной в реализации своего товара. К чести разработчика следует сказать, что после нескольких лет молчания по поводу фильтра "books" в глубине предлагаемой документации сегодня можно найти скромное упоминание об арендаторе фильтра. Ранее его владельца просто было нельзя идентифицировать, и только спустя некоторое время, становилось понятно, что система работает с довольно незначительной по объему и специфически пополняемой базой данных.
Не менее серьезно выглядят опасения, когда поиск связан с информацией, привязанной к определенному формату ее хранения, например, звуковым файлам. В течение нескольких месяцев поиск "звуков в Интернете" на Lycos оставался чем-то таинственным, напоминающим работу с небольшой, но со вкусом собранной коллекцией. Тестирование системы с помощью простых запросов показывало, что в основном в ней представлены форматы wav и au. Недавно стало известно, что теперь поддерживаются также и mp3, mid, ra , ram и aif. При этом объем накопленных записей, доступных через большинство фильтров, продолжает сохраняться в тайне.
Ясно, что если интересующий вас формат не входит в поддерживаемый на данный момент системой перечень, вы получите нулевой отклик, причину которого следовало бы четко представлять с самого начала.
Происхождение сопроводительных записей к звуковым файлам на Lycos, которые отображаются в результатах поиска, по-прежнему не регламентировано разработчиком.
Аналогичные проблемы существуют и на других ИПС. Хотелось бы отметить типичный в этом отношении прием: использование шаблона глобальной ИПС как для поиска информации, относящейся ко всему Интернет-простанству, так и для поиска по некоторым избранным базам данных или коллекциям. К сожалению, реальное поле поиска оговаривается далеко не всегда, и часто его приходится выяснять самостоятельно во избежание неверных выводов в дальнейшем.